算法学习(一)——介绍及环境安装

最近公司打算基于摄像头做自研算法,因此需要学习算法的基础知识以及一些常用的算法及技巧。学习东西需要一些技巧以及带有目的性的学习往往效率更高。所以从理解如下一些问题入门?
- 算法是什么
- 算法有哪些方面的应用
- 有哪些算法
- 算法开发前期准备
- 算法环境安装
- 算法上手体验
如果知道上面的内容基本上算是摸到算法的门了,但是能不能跨进门需要学习算法的实战应用,达到一定成都才能进行高阶应用,成为真正的算法工程师。
算法是什么?
了解这个问题首先得知道计算机视觉这个概念,简单来讲就是让计算机像人类视觉一样的感知世界。
人眼所看到的世界是平滑的流动的世界,任何物体的运动都是连贯的。但如果把时间分成很小的纬度,每一个时刻看到的其实也只是一张张的“照片”,而组成的这一张张照片不停的连续播放看起来就是连贯的,事实上人眼所看到的自然画面频率接近60帧。我们所知道摄像机其底层原理也是通过拍摄一张张的照片然后在播放器上以固定的频率播放出来。早期的电视播放频率也是每秒60帧,但是通过研究发现只要到达24帧,人眼就已经可以感觉到画面是连续的,意味着如果将这60帧均匀抽掉一些帧后也几乎无感觉到区别,所以现在的电视基本是30帧,而电影却只有24帧。当然少于这个帧的话播放的画面看起来会有跳跃感或者说是不连续,同理假如把本来2秒钟播放的图片以1秒钟来播放,或者1秒图片拉伸到2秒播放,人就会感觉到动作加快和减慢,这就是快放和慢放,快放和慢放这个不在我们算法的考虑之内。
基于如上的说明,我们知道每一帧都是一张图片,那么如果我在每张图片上面做点处理,比如在右上角加一朵花花,那么播放出来的画面就会在右上角显示一朵花花。所以,到这里就应该有个概念,算法真正的用处在哪里,不错,就是对这些图片的处理,并且不会只做加一朵花花这么简单的事情,而是更复杂的应用,比如加一些特效,在很多直播类的应用里面通常把这种功能叫做滤镜。当然还可以做识别,比如图片上的物体识别,这是更复杂的算法处理。如果这个工作交给机器来做,可以比人识别更快,但是错误率也可能更高,所以对于计算机来讲都需要一个容错率,随着机器性能的提高,算法的不断迭代完善,这个错误率已经越来越低,甚至某些场景的算法几乎可以达到100%。
所以算法是什么?总结下来算法就是对图片做的一系列处理,简单吧,但是这里的处理需要一些列的数学和图像学的知识做理论基础。
算法有哪些方面的应用?
自动驾驶:随着技术的发展,自动驾驶功能已在某些公司实现了,但是考虑到技术的成熟度,暂未大规模铺开,目前任然处于试验阶段。自动驾驶对需要的技术要求颇高,需要考虑到各种场景,白天/夜间,天气,路况,人行道,复杂道路,突发情况等等。
卫星图像:大的如宇宙图像,天体图像,小的如地面图像,建筑图像对图像的要求很高,3D,2D,热力图等等。
医疗影像:将医疗设备检测的内容以图像的形式显示在终端,比如孕妇肚子里的孩子,超声,心电图等等。
监控安检:每天过的地铁或者火车站的行李检查,酒店或者道路上的异常检测报警,公园的水面检测,山火检测
人脸、车牌号识别:每天上班人脸识别打卡,汽车泊车车牌号识别
当然算法的应用不止上面提到的这些,还有年龄识别,表情识别,物体识别等等。现在人们的生活已经离不开这些算法了,有的只是简单用到了算法,而有的用到了算法的衍生,比如通过摄像头可以统计每天进出店的人数,高峰期时段,夜间防控报警等等,有的离谱的还用于检测员工离开座位的时间,上厕所的时间,算法本身没有好恶之分,关键在用的人是否有好恶之分,不做过多评判。
现在对于算法的开发已经出现一大批专业的开发公司,这些公司主要负责挖掘算法需要的场景,然后开发出对应的算法卖给需要的人。
有哪些算法?
算法主要做的就是特征提取。早期靠人工来配置算法。主要采用两种方案
- SIFT:Scale-Invariant Feature Transform,尺度不变特征变换
- HOG:Histogram of Oriented Gradients,方向梯度直方图
具体的可以查相关资料,这里不做解释。当然现在更多的是采用深度学习的方式。这就利用到了卷积神经网络。卷积神经网络大概分为三层
- 卷积层
- 池化层
- 全连接层
在写这篇文章的时候,我只看到了卷积层,只有个粗浅的理解,大概是做滤波器的,每个滤波器提取一个或多个特征。而这些滤波器可以是一个或多个,可以自我学习的。
算法的分类主要分为单阶段目标检测算法和多阶段目标检测算法。
单阶段目标检测算法的特点在于它只需要一次提取特征即可实现目标检测,因此其速度通常比多阶段算法要快,尽管可能在精度上稍微低一些。代表算法如下
- yolo
- ssd
从github上来看,yolo目前用的最多,有48K左右的标星量,而ssd只有4K左右的标星量。
yolo分为多个版本以及其衍生版,最新版本为v8,常用的v5,下面是几个版本的比较。
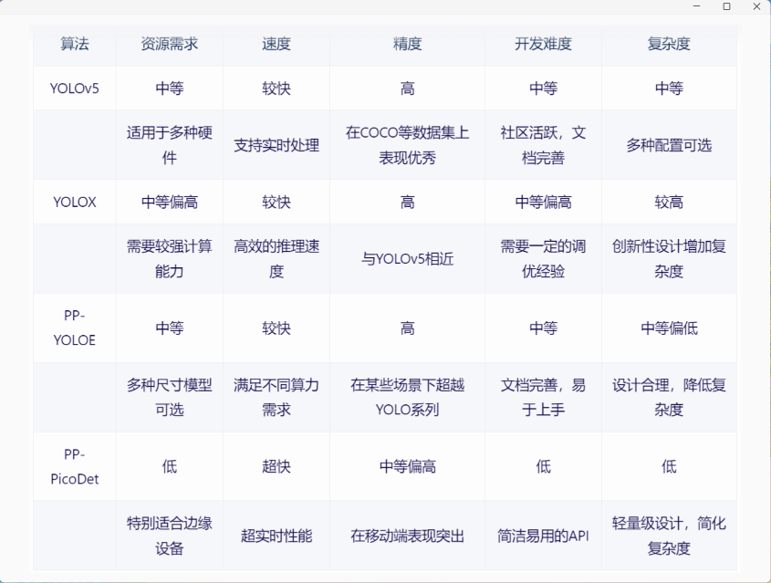
多阶段目标检测算法则采用了一种更为复杂、分步骤的处理方式,该算法一般用于对准确率要求极高的场景,代表算法如下:
- R-CNN
- FAST R-CNN
- FASTER R-CNN
下面是几个版本的比较
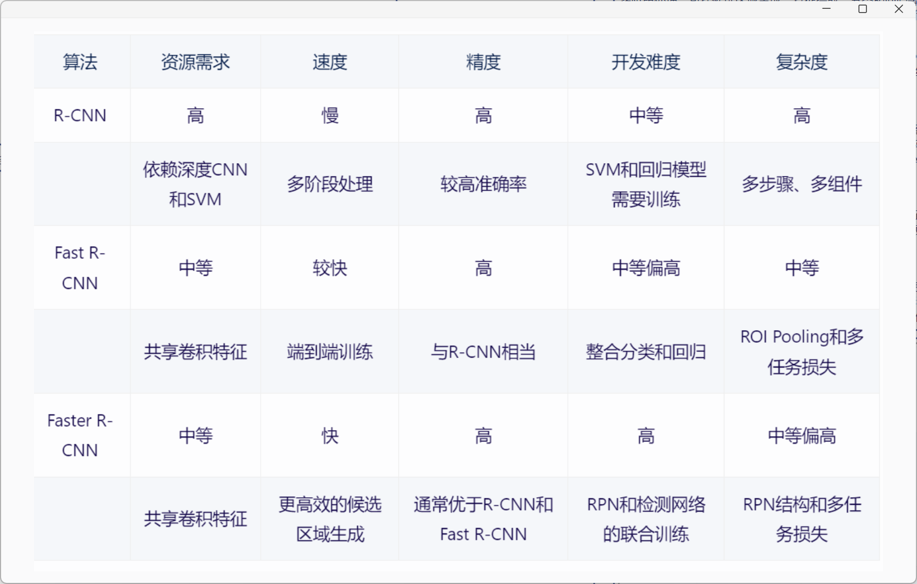
考虑到文档的完善度、出了错误能快速找到问题、开发难度、资源需求和运行速度。最终选择yolo算法,版本选择了yolov5.
算法开发的前期准备
本人 win11pc一台、已提前安装好python
算法环境安装
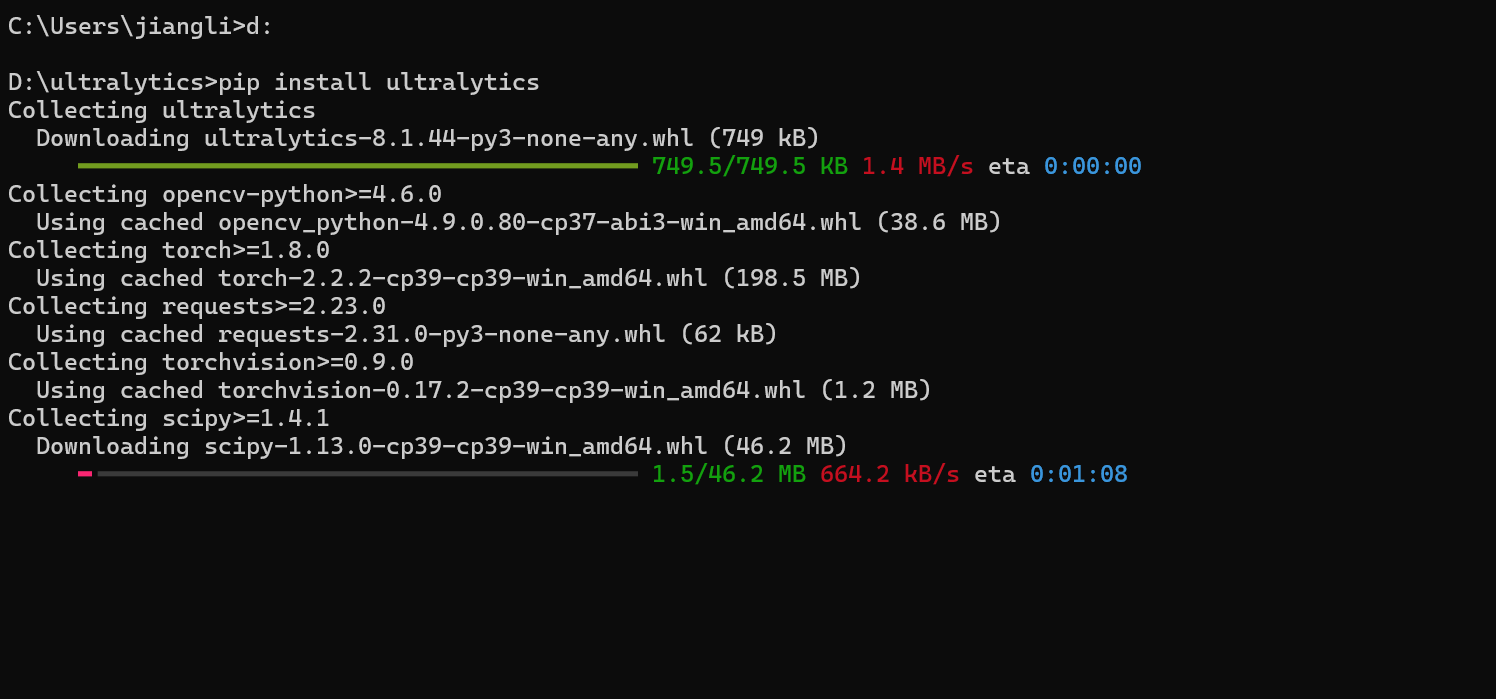
安装ultralytics
pip install ultralytics
安装过程,剩下的就是等待,过程都是自动的
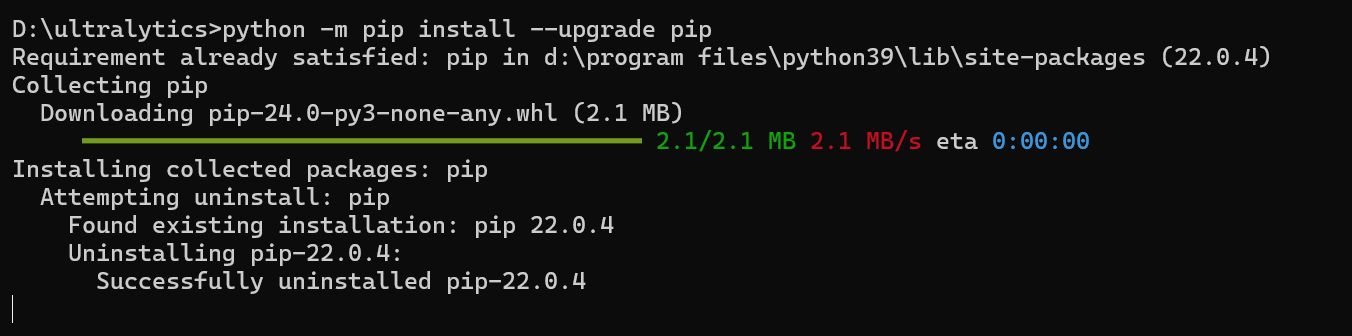
安装完成后可能会出现如下提示
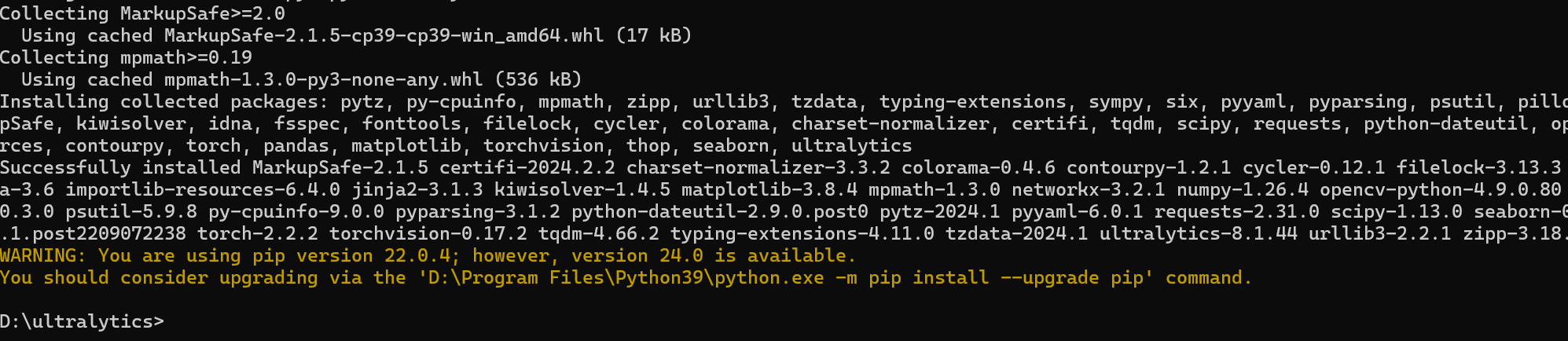
此时执行命令升级
python-m pip install--upgrade pip
正常升级
安装PyTorch
PyTorch需要根据环境来配置,去官网根据自己pc的配置选择合适的安装命令。
比如我这里的配置
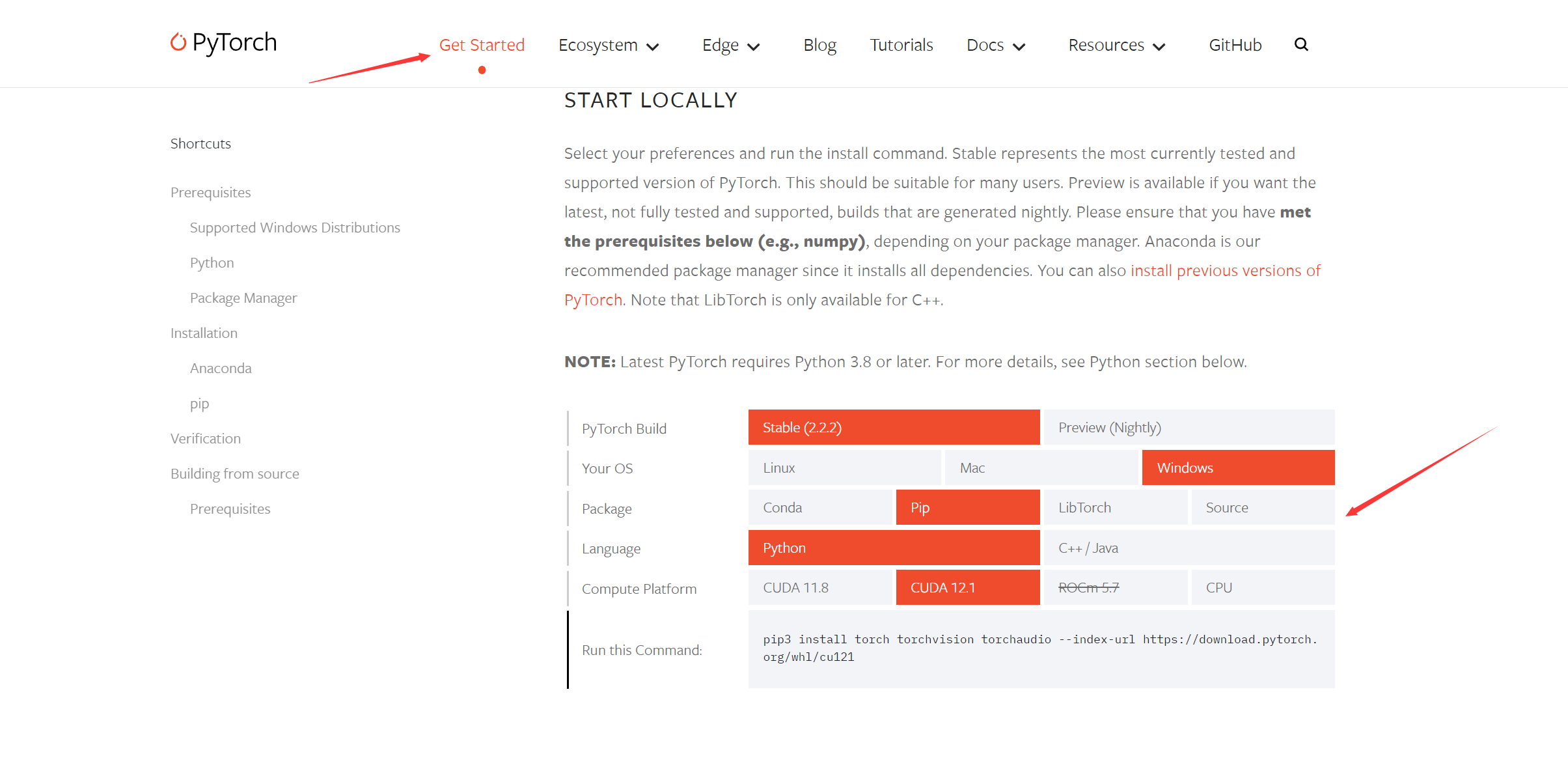
选择后下面有对应的安装方式
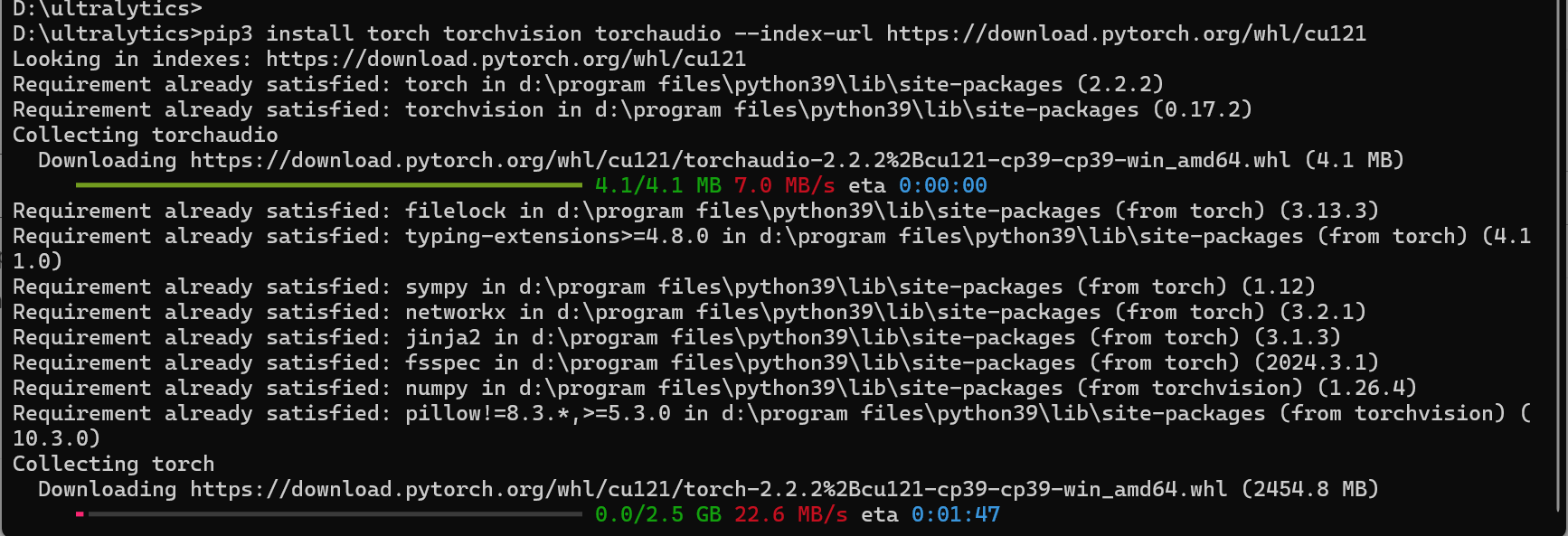
1 | pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121 |
安装如下
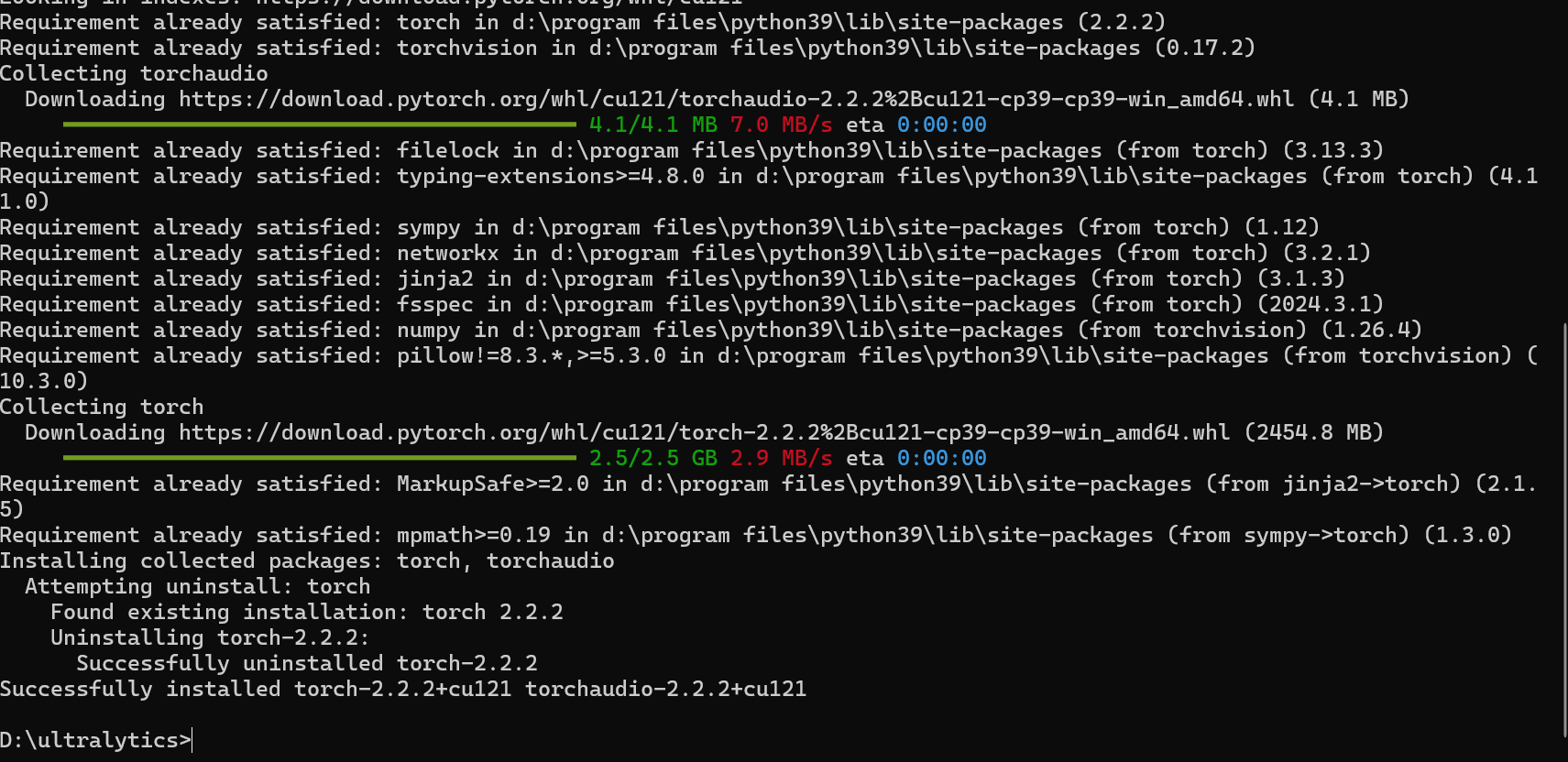
安装成功
安装opencv
openc官网下载最新版本,根据自己的环境安装。
至此,算法需要的环境基本安装完毕,下一节继续学习图像的基本处理
发表回复
要发表评论,您必须先登录。