算法学习(二)——图像处理

首先需要准备图片,最好带有人物的。我这里准备了两张图片

C:\Users\jiangli\Desktop\11\图片\test.jpg

C:\Users\jiangli\Desktop\11\图片\face.jpg
导入工具包
1 2 3 4 | # 图像工具包import cv2# 数学工具包import numpy as ny |
展示图片
1 2 3 4 | img = cv2.imread("C:\\Users\\jiangli\\Desktop\\11\\图片\\test.jpg")cv2.imshow("test111",img)# cv2.imwrite("D:\\pyspace-yolodemo\\images\\test.jpg",img) #保存图片到指定位置cv2.waitKey(0) |
imshow的第一个参数为该展示图片进行命名,而waitKey(0)表示按下任意键退出,如果不写该语句,则程序将直接执行完毕,不方便观察展示图片的效果
执行结果

展示图片属性
比如图片的宽高、大小、颜色分量
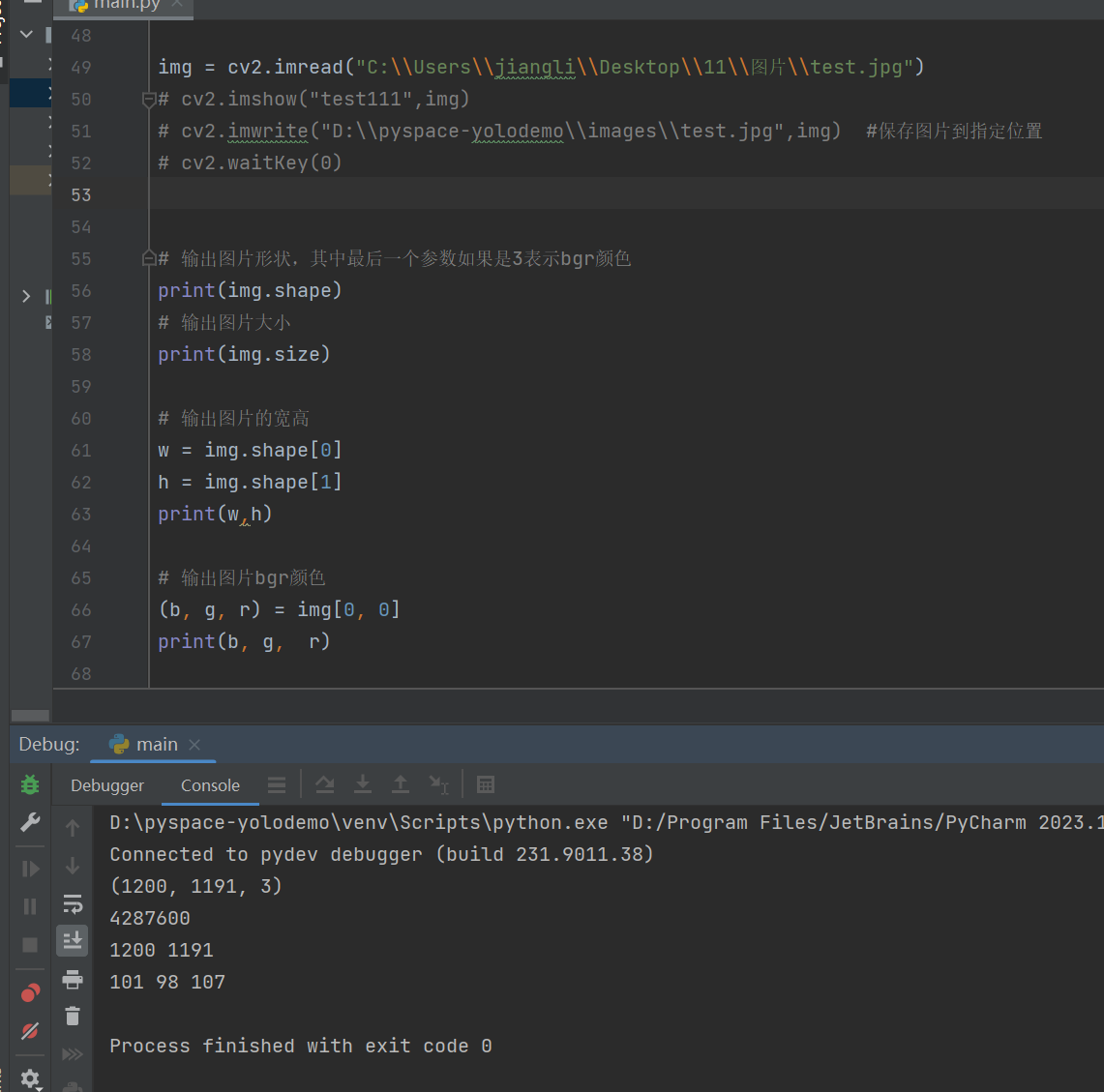
1 2 3 4 5 6 7 8 9 10 11 12 13 | # 输出图片形状,其中最后一个参数如果是3表示bgr颜色print(img.shape)# 输出图片大小print(img.size)# 输出图片的宽高w = img.shape[0]h = img.shape[1]print(w,h)# 输出图片bgr颜色(b, g, r) = img[0, 0]print(b, g, r) |
执行结果
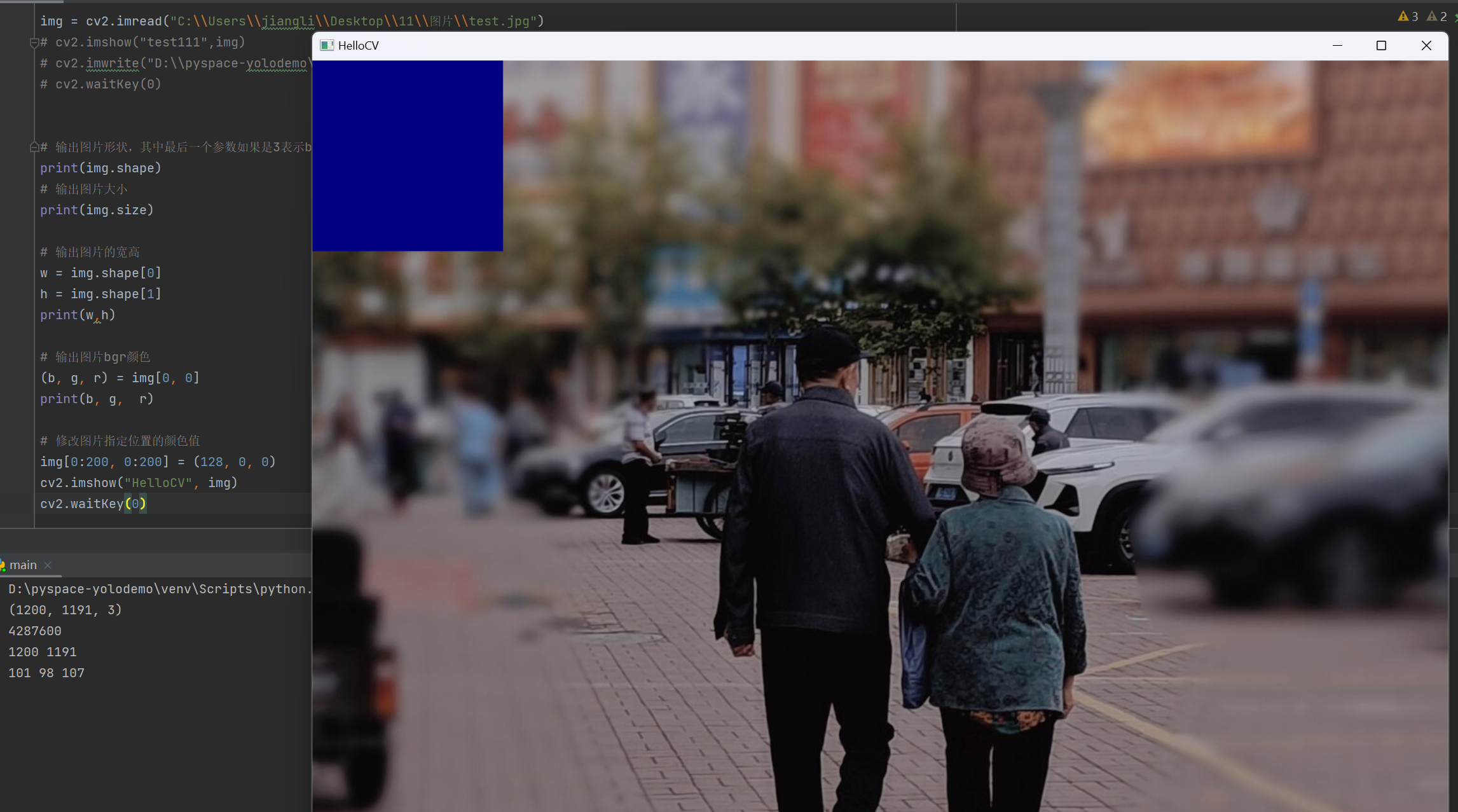
修改图片指定位置的颜色值
1 2 3 | img[0:200, 0:200] = (128, 0, 0)cv2.imshow("HelloCV", img)cv2.waitKey(0) |
执行结果
在图片上面画矩形以及在旁边输出一段文字
1 2 3 4 5 6 | red = (0, 0, 255) # b g rfont = cv2.FONT_HERSHEY_COMPLEX_SMALL # 字体大小cv2.putText(img, "title", (100, 90), font, 4, red)cv2.rectangle(img, (100, 100), (400, 400), red, 0) # 0:空心, -1:实心cv2.imshow("HelloCV", img)cv2.waitKey(0) |
执行结果

平移图像
1 2 3 4 5 6 | # 创建一个变换矩阵# 平移:x轴正方向(1,0) 200, y轴正方向(0,1) 100M = ny.float32([[1, 0, 200], [0, 1, 100]])dst = cv2.warpAffine(img, M, (w, h))cv2.imshow("Hello", dst)cv2.waitKey(0) |
执行结果

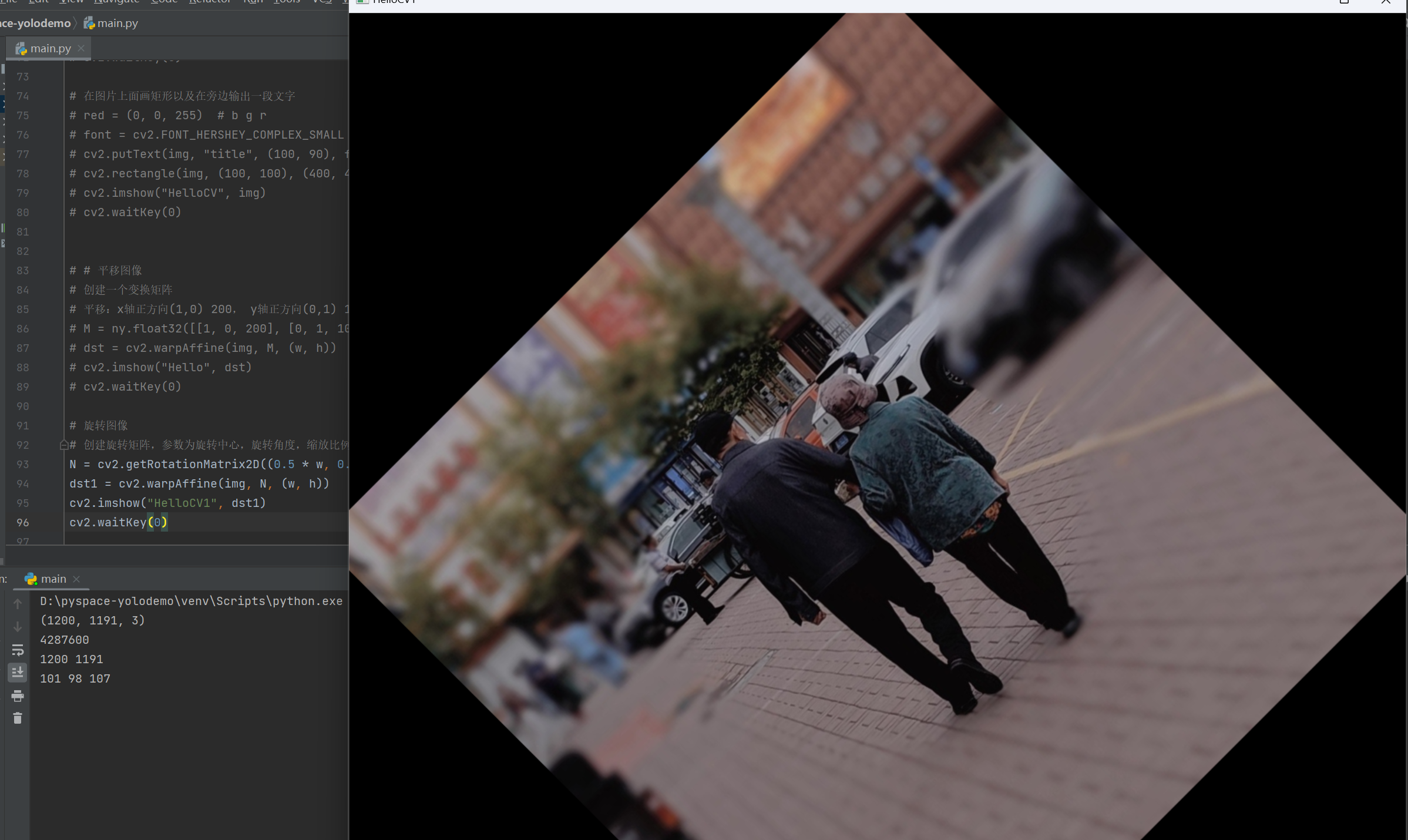
旋转图像
1 2 3 4 5 | # 创建旋转矩阵,参数为旋转中心,旋转角度,缩放比例N = cv2.getRotationMatrix2D((0.5 * w, 0.5 * h), 45, 0.75)dst1 = cv2.warpAffine(img, N, (w, h))cv2.imshow("HelloCV1", dst1)cv2.waitKey(0) |
执行结果
合并通道
1 2 3 4 5 6 7 8 | # 拆分成3个颜色分量通道图片(B, G, R) = cv2.split(img)cv2.imshow("blue", B)cv2.imshow("green", G)cv2.imshow("red", R)merge = cv2.merge([B, G, R]) #合并通道cv2.imshow("merge", merge)cv2.waitKey(0) |
执行结果

边缘检测1
1 2 3 4 5 6 7 | gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换为灰度图,以便运算# cv2.imshow("gray",gray)lab = cv2.Laplacian(img, cv2.CV_64F) # 深度cv2.imshow("lab1",lab)lab = ny.uint8(ny.absolute(lab)) # 绝对值化cv2.imshow("lab2", lab)cv2.waitKey(0) |
执行结果
边缘检测2
1 2 3 4 | # canny像素值范围200到240canny = cv2.Canny(img, 200, 240)cv2.imshow("canny", canny)cv2.waitKey(0) |
执行结果
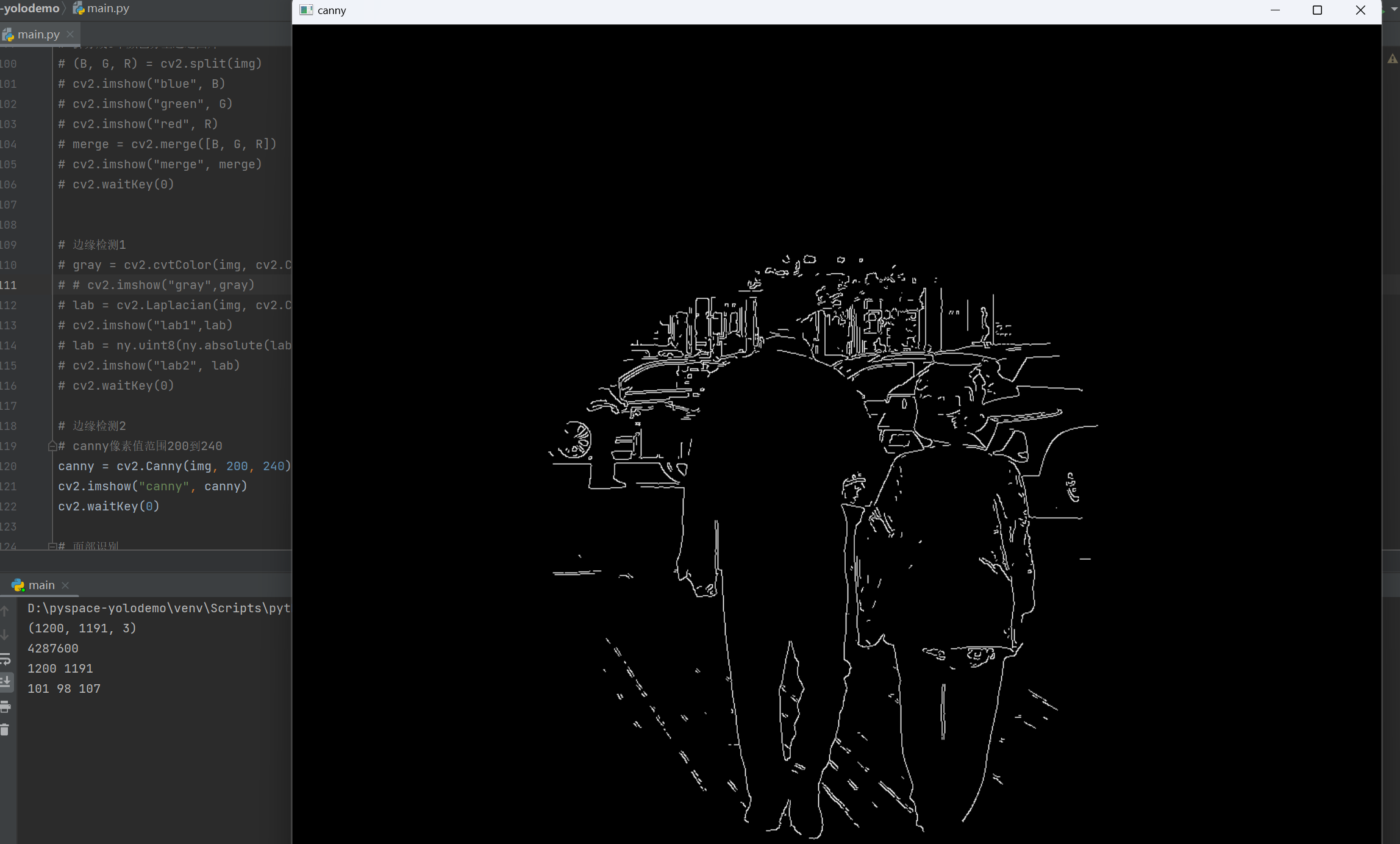
图片面部识别
1 2 3 4 5 6 7 8 9 10 11 12 | imgFace = cv2.imread("C:\\Users\\jiangli\\Desktop\\11\\图片\\face.png")cas = cv2.CascadeClassifier("face/haarcascade_frontalface_alt2.xml") # 载入级联分类器,即人脸数据库gray = cv2.cvtColor(imgFace, cv2.COLOR_BGR2GRAY) # 转换为灰度图,以便运算# 检测人脸:跟数据库进行比较# 结果集合:每个结果包含人脸的坐标x, y, 长度, 宽度rects = cas.detectMultiScale(gray)# 循环结果集合在画面上绘制矩形for x, y, width, height in rects:cv2.rectangle(imgFace, (x, y), (x + width, y + height), (0, 0, 255), 3)cv2.imshow("face", imgFace)cv2.waitKey(0) |
执行结果
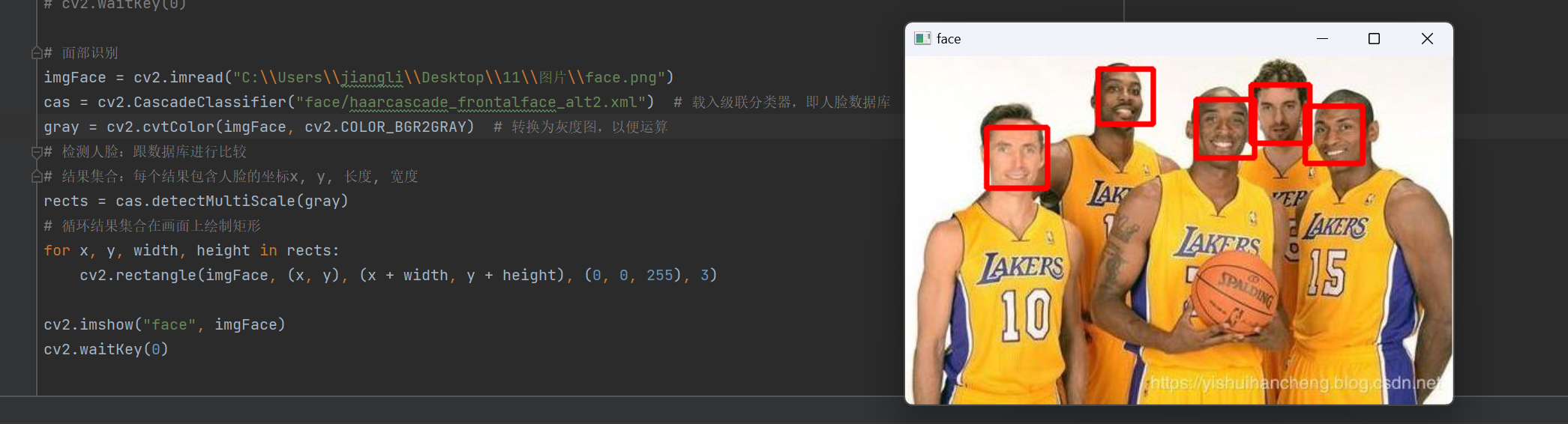
视频面部识别
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | # 摄像头编号0(默认) 1 2 3 必须要有参数camera = cv2.VideoCapture(0) # 从摄像头读取# camera = cv2.VideoCapture("C:\\Users\\jiangli\\Desktop\\11\\视频\\trailer.mp4") # 从指定的视频读取# python语法,用缩进表示代码块,相当于c的括号while True: # 读取一帧图像,ret为是否读到的返回值,img为读到的图像 (ok, img) = camera.read() if not ok: # print("open video failed") break else: # print("open video success") cas = cv2.CascadeClassifier("face/haarcascade_frontalface_alt2.xml") # 载入级联分类器,即人脸数据库 gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换为灰度图,以便运算 # 检测人脸:跟数据库进行比较 # 结果:人脸的坐标x, y, 长度, 宽度 rects = cas.detectMultiScale(gray) for x, y, width, height in rects: cv2.rectangle(img, (x, y), (x + width, y + height), (0, 0, 255), 3) cv2.imshow("face", img) if cv2.waitKey(33) & 0xFF == ord('q'): # 等待33毫秒,输入q跳出 breakcamera.release()cv2.destroyAllWindows()cv2.waitKey(0); |
执行结果
发表回复
要发表评论,您必须先登录。